Key-Value Pairs Extraction Automatically Extract Data from Documents
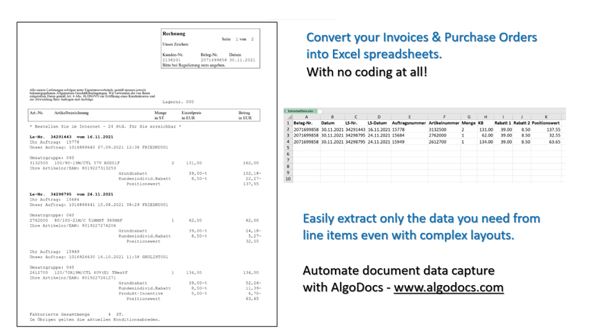
You’re drowning in scanned documents: PDFs, images, you name it. You need the key facts and figures, but who has time to search through all that text? What you need is a sidekick to scan those docs and pull out just the data you want. Meet AlgoDocs – your new KVP extraction buddy. In just a few clicks, it can dig through any scanned document and serve up those precious key-value pairs on a platter. No more squinting at tiny text or getting lost in paragraphs. Just the facts, fast. Whether you’re analyzing financials, reviewing contracts, or prepping reports, AlgoDocs has your back. It’s like having a personal data assistant to lighten your load. Read on to see how this tool can help tame your document chaos.
The Challenge of Extracting Key-Value Pairs from Documents
Extracting key-value pairs from unstructured documents can be tricky. The documents you want to extract data from likely come in all shapes, sizes, and layouts. Some may be neatly organized while others are messy and chaotic. The key-value relationships aren’t always clearly labeled or even visually aligned.
To automatically extract this data, an algorithm has to be able to identify what pieces of information act as “keys” (like names, dates, locations, total, etc.) and what pieces act as the corresponding “values” (like ages, addresses, or descriptions). The algorithm also has to determine how to match up the keys and values correctly, even when they aren’t neatly presented in a table or list.
Some of the obstacles the algorithm faces include:
• Ambiguous or implied keys: The key may not be explicitly stated but rather implied, forcing the algorithm to infer what the key is based on the context.
• Values located far from keys: The value could be sentences or even paragraphs away from the key, making the connection difficult to determine.
• Repeated or re-used keys: The same key may be used multiple times, and the algorithm has to figure out which value corresponds to which use of the key.
• Irregular layouts: Keys and values may be scattered in unexpected places rather than in a neat table or bulleted list. The algorithm has to scan the entire document layout to locate them.
• Varied data types: Keys and values could be names, dates, locations, descriptions, or a mix of types, adding complexity. The algorithm must be able to handle extracting all these data types accurately.
• Ambiguous values: A value could potentially relate to more than one key, and the algorithm has to determine the most likely match based on the context.
With machine learning and natural language processing, algorithms are getting better at overcoming these obstacles and extracting high-quality key-value pairs from even the most challenging documents. But it remains a difficult task that requires a smart, nuanced approach. With more data and continued progress in ML, algorithms will gain a deeper understanding of how to read and interpret documents the way humans do.
Introducing AlgoDocs for Automated Key-Value Pairs Extraction
AlgoDocs is an AI-powered web app that can extract key-value pairs and structured data from documents of any layout. It uses advanced OCR (optical character recognition) and machine learning models to identify and capture keys, labels, and their associated values from PDFs scanned files, and images.
You can use the AlgoDocs web app or API and their algorithms will get to work. Note that the extracted data is returned to you in a structured format like XML, XLS, JSON, or CSV format for easy importing into other systems.
Give It a Try
Ready to experience the power of automated data extraction? Sign up for a free AlgoDocs account and start uploading your documents today. 50 pages each month are free, so you have nothing to lose. Why spend hours manually entering data when AlgoDocs can do the work for you in just a few clicks? Give it a try and see how much time you can save!
Benefits of Automated Key-Value Pairs Extraction
Automated key-value pairs extraction offers some major benefits.
- One of the biggest benefits is how much time it can save. Manually extracting data from documents is tedious and labor-intensive work. An automated solution can plow through huge volumes of documents quickly and efficiently extract the relevant data, saving countless hours of human effort.
- Accuracy and consistency are also improved. Humans get tired and make mistakes, especially when doing repetitive tasks like data entry. Software, on the other hand, can extract data precisely and consistently every time. It won’t accidentally skip data or enter it incorrectly due to fatigue or boredom.
- Automation reduces costs. Paying employees to manually extract data from documents is expensive. Automated solutions require an upfront investment but can then handle huge workloads at a fraction of the cost. The more documents and data you need to process, the more you can save.
- Integrating the extracted data is seamless. The data can be exported in a format that is easily imported into other systems and databases for further processing and analysis. This makes the data much more useful and impactful.
In summary, automated key-value pairs extraction can save time, improve accuracy, reduce costs, enable easy data integration, and minimize risks – all of which help organizations unlock the potential of their data. Extracting key insights and trends from data is critical, and automation makes that possible on a massive scale.





